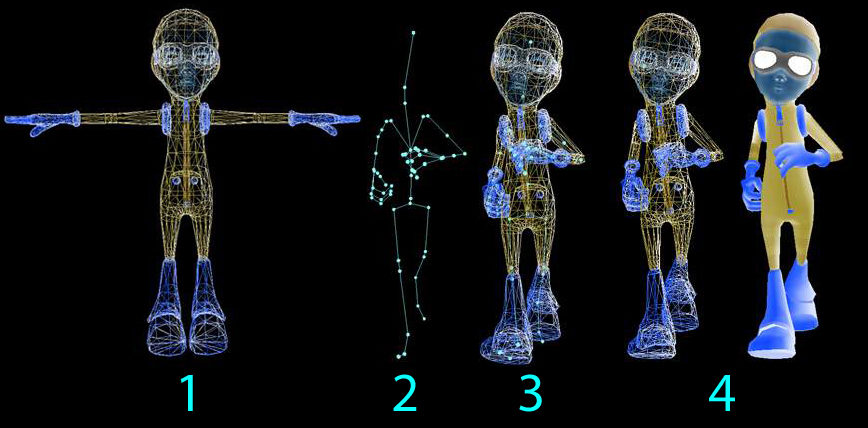
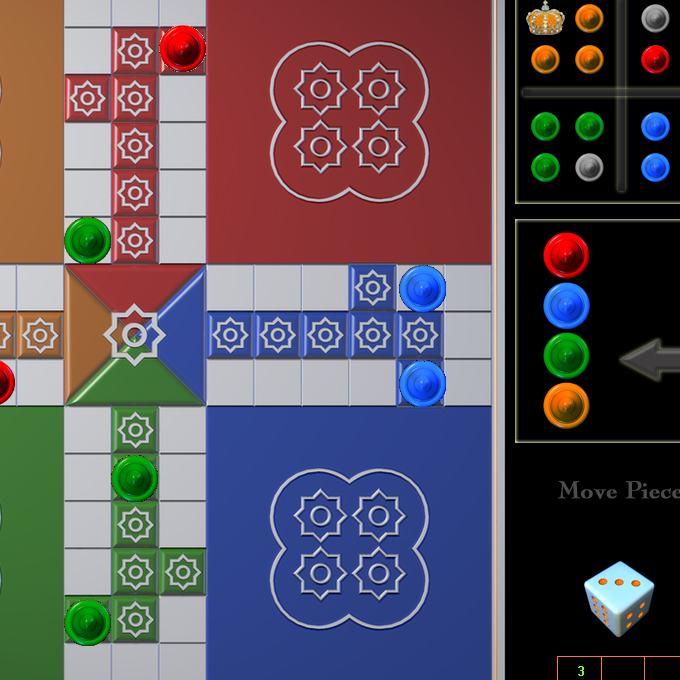
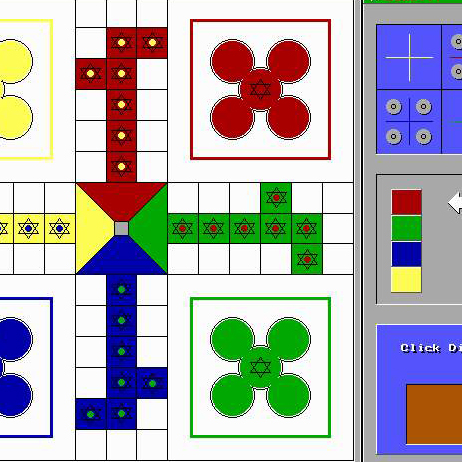
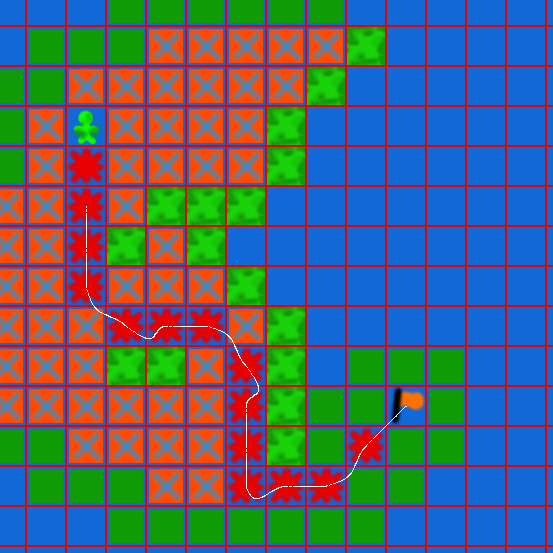
Hello World! If you are here for the Collada Tutorials Please follow the links COLLADA TUTORIAL COLLADA TUTORIAL ASSETS (AstroBoy Walk)Download Projects and Sample Codes Roar Engine Luddo Game Ludd Game 4 Bit Particles Projectiles Astar Implementation Roshni Typing Tutor Collada Exporter BreakOut Game LUA Scripts GUI